Формулировка проблемы
Предположим у вас есть PDF файл, но он слишком большой и вы бы хотели его сжать. Возможно вы хотите уменьшить размер чтобы можно было быстрее отправить через интернет, или сохранить место на жестком диске.
Всё усложняется, когда у вас много таких файлов PDF которые нужно сжать.
Конечно существуют онлайн сервисы, позволяющие это сделать. Но обычно они позволяют обработать ограниченное количество файлов за раз. Также потребуется длительное время для загрузки оригиналов, а потом на скачивание обработанных файлов. И возможно вам было бы не комфортно делиться своими файлами в интернете (вопрос конфиденциальности).
К счастью все эти задачи мы можем переложить на Python. Но перед тем как разобрать как это сделать, давайте немного узнаем о PDF файлах.
О сжатии PDF файлов
Согласно словам Дова Айзекса, бывшего главного научного сотрудника Adobe, PDF-документы уже существенно сжаты.
Части документа с текстом и векторной графикой уже сжаты zipом, поэтому возможностей дальнейшего сжатия не много.
Улучшение сжатия можно добиться путем сжатия частей PDF содержащих изображения, правда придется пожертвовать их качеством.
Итак, сжатие PDF достижимо, но придется выбирать между силой сжатия и тем, сколько мы сможем пожертвовать качеством изображений.
Настройка
Программист Theeko74 написал, Python скрипт «pdf_compressor.py». Этот скрипт представляет собой оболочку для ghostscript функций, которые выполняют основную работу по сжатию PDF файлов.
Этот скрипт распространяется по лицензии MIT и его можно использовать как пожелаете.
Важно: чтобы скрипт работал, нужно чтобы на вашем компьютере был установлен ghostscript. Скачать установщик ghostscript можно на сайте.
Скачайте скрипт pdf_compressor.py с GitHub отсюда.
Теперь приступим к написанию нашего скрипта по сжатию PDF файлов.
Создадим папку pdf_comp и создадим в ней наш скрипт. В этом примере я использую ОС Windows и SublimeText3 в качестве редактора кода. Вы можете использовать любой другой редактор, который вам нравится больше.
Сам скрипт назовем «app.py». Теперь импортируем в наш скрипт «pdf_compressor.py», импортируем как модуль.
Чтобы это сделать, надо создать поддиректорию в папке где находится наш скрипт. Также надо скопировать в эту поддиректорию скрипт «pdf_compressor.py». В этой же папке надо создать файл «__init__.py» (в названии используется двойное нижнее подчеркивание с обеих сторон от init).
Таким образом мы создали локальный пакет pdf_comp, содержащий модуль pdf_compressor.py. Теперь настало время написать скрипт.
Скрипт Python для сжатия PDF
Вот наш скрипт:
from pdf_compressor.pdf_compressor import compress
compress('06-2022.pdf', '06-2022comp.pdf', power=4)
input('Press ENTER to exit')Как видите, это очень маленький скрипт.
Сначала мы импортируем функцию «compress» из модуля «pdf_compressor».
Затем вызываем функцию «compress» и передаём в качестве аргументов параметры: входящий файл (который требуется обработать), итоговый файл и аргумент «power» (степень сжатия). В конец скрипта я добавил input, чтобы после выполнения скрипт сразу не закрылся и можно было посмотреть подробности выполнения.
Степени сжатия можно указать следующие:
- 0 — default (качество по умолчанию)
- 1 — prepress (предпечатная подготовка)
- 2 — printer (печать)
- 3 — ebook (электронная книга)
- 4 — screen (экран)
Чем больше значение «power» тем ниже качество изображений в итоговом файле и меньше его размер (сильнее сжатие).
Запуск скрипта
Теперь можно запустить скрипт:
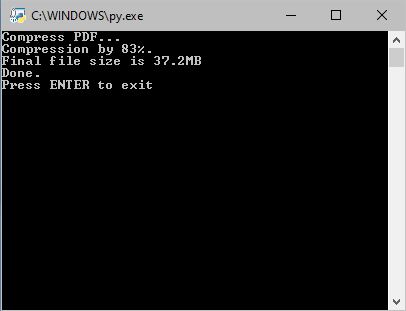
Размер обрабатываемого файла до обработки был 210.8mb, на выходе получилось 37.2mb. Сжатие составило 83%.
В этом примере мы сжали один документ, но если модифицировать скрипт, можно будет запускать его в циклично, обрабатывая сразу несколько файлов сразу. Однако, оставим это на упражнение для читателя.